訳注: 原文とデータはこちら SRS Benchmark
SRS ベンチマーク (性能評価テスト)
はじめに
間隔反復アルゴリズムは、フラッシュカードのレビューをスケジュールするのに役立つコンピュータプログラムです。良い間隔反復アルゴリズムは、より効率的に物事を覚えるのに役立ちます。一度に詰め込むのではなく、時間をかけてレビューを分散させます。これを効率的に行うために、これらのアルゴリズムはあなたの記憶の仕組みを理解しようとします。いつ何かを忘れそうかを予測し、それに応じてレビューをスケジュールすることを目指しています。
このベンチマークは、さまざまなアルゴリズムの予測精度を評価するために設計されたツールです。多くのアルゴリズムが評価され、最も正確な予測を提供するものを見つけ出します。
データセット
SRSベンチマークのデータセットは、フラッシュカードアプリであるAnkiを使用する2万人から提供されたものです。合計で、このデータセットには約17億回のフラッシュカードレビューに関する情報が含まれています。完全なデータセットはHugging Face Datasetsにホストされています: open-spaced-repetition/FSRS-Anki-20k。
評価
データ分割
SRSベンチマークでは、TimeSeriesSplitというツールを使用します。これは機械学習に使用されるsklearnライブラリの一部です。このツールはデータを時間で分割するのに役立ちます。古いレビューはトレーニングに使用し、新しいレビューはテストに使用します。これにより、アルゴリズムに与えるべきでない未来の情報を誤って与えることを防ぎます。実際には、過去の学習セッションを使用して未来のセッションを予測します。これにより、TimeSeriesSplitはベンチマークに適しています。
注意: TimeSeriesSplitは評価から最初の分割を除外します。これは最初の分割がトレーニングに使用され、同じデータでアルゴリズムを評価したくないためです。
メトリクス
SRSベンチマークでは、これらのアルゴリズムがどれだけうまく機能するかを評価するために、ログ損失、AUC、およびカスタムRMSE(RMSE (bins))の3つのメトリクスを使用します。
- ログ損失(Binary Cross Entropyとも呼ばれる): 主にバイナリ分類問題に適用されるために利用され、ログ損失は予測されたリコール確率とレビュー結果(1または0)の間の不一致を測定します。これは、アルゴリズムが真のリコール確率をどれだけ正確に近似するかを定量化し、間隔反復システムにおけるアルゴリズム評価の重要なメトリクスとなります。ログ損失は0から無限大までの範囲で、低いほど良いです。
- AUC(ROC曲線下面積): AUCは分離度の程度または測定を表します。これは、アルゴリズムがクラス間をどれだけ区別できるかを示します。AUCは0から1の範囲ですが、実際にはほとんどの場合0.5より大きくなります。高いほど良いです。
- ビン内の二乗平均平方根誤差(RMSE (bins)): これはSRSベンチマークで使用するために設計されたメトリクスです。このアプローチでは、予測とレビュー結果が間隔の長さ、レビューの回数、およびラプスの回数に基づいてビンにグループ化されます。各ビン内で、平均予測リコール確率と平均リコール率の間の二乗差が計算されます。これらの値は各ビンのサンプルサイズに応じて重み付けされ、最終的な重み付けされた二乗平均平方根誤差が計算されます。このメトリクスは、異なる確率範囲にわたるアルゴリズムの性能を詳細に理解するためのものです。詳細については、メトリックを参照してください。RMSE (bins)は0から1の範囲で、低いほど良いです。
アルゴリズム
- FSRS v3: 実際に使用された最初のFSRSアルゴリズムのバージョン。
- FSRS v4: コミュニティの助けを借りて改良されたFSRSのアップグレード版。
- FSRS-4.5: FSRS v4に基づいてわずかに改良されたバージョン。忘却曲線の形状が変更されています。このベンチマークには、デフォルトパラメータ(20,000のコレクションすべてでFSRS-4.5を実行して取得されたもの)を使用したFSRS-4.5と、最初の4つのパラメータ(最初のレビュー後の初期安定性の値)のみを最適化し、残りはデフォルトに設定したFSRS-4.5が含まれています。
- FSRS-5: 最新のFSRSバージョン。以前のバージョンとは異なり、同日レビューを考慮に入れています。同日レビューはトレーニングにのみ使用され、評価には使用されません。
- FSRS-rs: FSRS-5のRust移植版。詳細はこちら: https://github.com/open-spaced-repetition/fsrs-rs
- GRU: データのシーケンスに基づいて予測を行うために頻繁に使用されるニューラルネットワークの一種。時間関連のタスクにおける機械学習の古典です。
- GRU-P: 忘却曲線を取り除き、リコールの確率を直接予測するGRUのバリアント。
- GRU-P-short: 上記と同じですが、同日レビューも考慮に入れています。
- DASH: この論文で提案されたモデル。名前はDifficulty(難易度)、Ability(能力)、Study History(学習履歴)を表します。このベンチマークでは、データセットに適用できないため、難易度部分を除いたAbilityとStudy Historyのみを使用しています。また、このモデルの他の2つのバリアントであるDASH[MCM]とDASH[ACT-R]も追加しました。詳細については、この論文を参照してください。
- ACT-R: この論文で提案されたモデル。宣言的記憶の活性化ベースのシステムを含みます。記憶痕跡の活性化によって間隔効果を説明します。
- HLR: Duolingoによって提案されたモデル。正式名称はHalf-Life Regressionです。詳細については、この論文を参照してください。
- Transformer: 自然言語処理において優れた性能を発揮するため、近年人気を集めているニューラルネットワークの一種。ChatGPTはこのアーキテクチャに基づいています。
- SM-2: SuperMemoによって使用された初期のアルゴリズムの1つで、最初の間隔反復ソフトウェアです。30年以上前に開発され、現在でも人気があります。AnkiのデフォルトアルゴリズムはSM-2に基づいています、Mnemosyneもそれを使用しています。このアルゴリズムはリコールの確率をネイティブに予測しないため、ベンチマークのために忘却曲線に関するいくつかの仮定に基づいて出力を変更しました。
- NN-17: SM-17のニューラルネットワーク近似。パラメータの数が同等であり、我々の推定によれば、SM-17と同様の性能を発揮します。
- AVG: ユーザーの平均保持率に等しい定数を出力する「アルゴリズム」。実用的な用途はなく、ベースラインとしてのみ機能します。
FSRSアルゴリズムに関する詳細は、次のWikiページを参照してください: The Algorithm.
結果
総ユーザー数: 19,990人。
評価に使用された総レビュー数: 702,721,850回。 同日レビューはFSRS-5およびGRU-P-shortを除いて除外されています。つまり、各アルゴリズムは1日につき1回のレビュー(時間順に最初のもの)しか使用しません。いくつかのレビューはフィルタリングされています。例えば、期日を手動で変更したり、「このデッキでの回答に基づいてカードを再スケジュールする」が無効になっているフィルターデッキでカードをレビューした場合に作成されたrevlogエントリなどです。最後に、外れ値フィルターが適用されます。これらの理由により、評価に使用されたレビュー数は以前に述べた17億回という数字よりも大幅に少なくなっています。
以下の表は、平均値と99%信頼区間を示しています。最良の結果は太字で強調されています。最右列には最適化可能(トレーニング可能)なパラメータの数が示されています。パラメータが定数である場合、それは含まれていません。
レビュー数で重み付け
| モデル | パラメータ数 | ログ損失 | RMSE(ビン) | AUC |
|---|---|---|---|---|
| GRU-P-short | 297 | 0.313±0.0051 | 0.0420±0.00085 | 0.707±0.0029 |
| GRU-P | 297 | 0.318±0.0053 | 0.0435±0.00091 | 0.697±0.0027 |
| FSRS-5 | 19 | 0.320±0.0052 | 0.050±0.0010 | 0.700±0.0028 |
| FSRS-rs | 19 | 0.322±0.0053 | 0.052±0.0011 | 0.692±0.0029 |
| FSRS-4.5 | 17 | 0.324±0.0053 | 0.052±0.0011 | 0.693±0.0027 |
| FSRSv4 | 17 | 0.329±0.0056 | 0.057±0.0012 | 0.690±0.0027 |
| DASH | 9 | 0.331±0.0053 | 0.060±0.0010 | 0.642±0.0031 |
| DASH[MCM] | 9 | 0.331±0.0054 | 0.062±0.0011 | 0.644±0.0030 |
| DASH[ACT-R] | 5 | 0.334±0.0055 | 0.065±0.0012 | 0.632±0.0031 |
| FSRSv3 | 13 | 0.360±0.0068 | 0.070±0.0015 | 0.667±0.0029 |
| FSRS-5-pretrain | 4 | 0.338±0.0058 | 0.072±0.0016 | 0.685±0.0028 |
| NN-17 | 39 | 0.346±0.0069 | 0.075±0.0015 | 0.595±0.0031 |
| GRU | 39 | 0.375±0.0072 | 0.079±0.0016 | 0.658±0.0027 |
| FSRS-5-dry-run | 0 | 0.346±0.0060 | 0.081±0.0017 | 0.681±0.0028 |
| ACT-R | 5 | 0.354±0.0057 | 0.084±0.0019 | 0.536±0.0030 |
| AVG | 0 | 0.354±0.0059 | 0.085±0.0019 | 0.508±0.0029 |
| HLR | 3 | 0.404±0.0079 | 0.102±0.0020 | 0.632±0.0034 |
| SM2 | 0 | 0.54±0.012 | 0.147±0.0029 | 0.599±0.0031 |
| Transformer | 127 | 0.51±0.011 | 0.182±0.0033 | 0.515±0.0043 |
重み付けなし
| Model | Parameters | Log Loss | RMSE (bins) | AUC |
|---|---|---|---|---|
| GRU-P | 297 | 0.345±0.0030 | 0.0655±0.00082 | 0.679±0.0017 |
| GRU-P-short | 297 | 0.340±0.0030 | 0.0659±0.00084 | 0.687±0.0019 |
| FSRS-5 | 19 | 0.346±0.0031 | 0.0712±0.00084 | 0.697±0.0017 |
| FSRS-rs | 19 | 0.348±0.0031 | 0.0726±0.00086 | 0.693±0.0017 |
| FSRS-4.5 | 17 | 0.352±0.0032 | 0.0742±0.00088 | 0.688±0.0017 |
| DASH | 9 | 0.358±0.0031 | 0.0810±0.00095 | 0.632±0.0018 |
| FSRSv4 | 17 | 0.362±0.0033 | 0.082±0.0010 | 0.685±0.0016 |
| DASH[MCM] | 9 | 0.358±0.0030 | 0.0831±0.00094 | 0.636±0.0019 |
| DASH[ACT-R] | 5 | 0.362±0.0033 | 0.086±0.0011 | 0.627±0.0019 |
| FSRS-5-pretrain | 4 | 0.359±0.0032 | 0.0866±0.00091 | 0.692±0.0016 |
| NN-17 | 39 | 0.380±0.0035 | 0.100±0.0013 | 0.570±0.0018 |
| FSRS-5-dry-run | 0 | 0.373±0.0032 | 0.101±0.0011 | 0.691±0.0016 |
| AVG | 0 | 0.385±0.0036 | 0.101±0.0011 | 0.500±0.0018 |
| ACT-R | 5 | 0.395±0.0040 | 0.106±0.0012 | 0.524±0.0018 |
| FSRSv3 | 13 | 0.422±0.0046 | 0.106±0.0013 | 0.661±0.0017 |
| GRU | 39 | 0.440±0.0052 | 0.108±0.0013 | 0.650±0.0017 |
| HLR | 3 | 0.456±0.0051 | 0.124±0.0013 | 0.636±0.0018 |
| Transformer | 127 | 0.554±0.0064 | 0.185±0.0018 | 0.527±0.0021 |
| SM2 | 0 | 0.71±0.013 | 0.199±0.0021 | 0.604±0.0018 |
レビュー数で重み付けされた平均は、データが豊富にある場合の「ベストケース」パフォーマンスをよりよく表しています。ほとんどすべてのアルゴリズムは、学習するデータが多いほど良いパフォーマンスを発揮するため、レビュー数で重み付けすることは平均を低い値に偏らせます。
重み付けされていない平均は、「平均的なケース」のパフォーマンスをよりよく表しています。実際には、すべてのユーザーが何十万ものレビューを持っているわけではないので、アルゴリズムが常にその完全な潜在能力を発揮できるわけではありません。
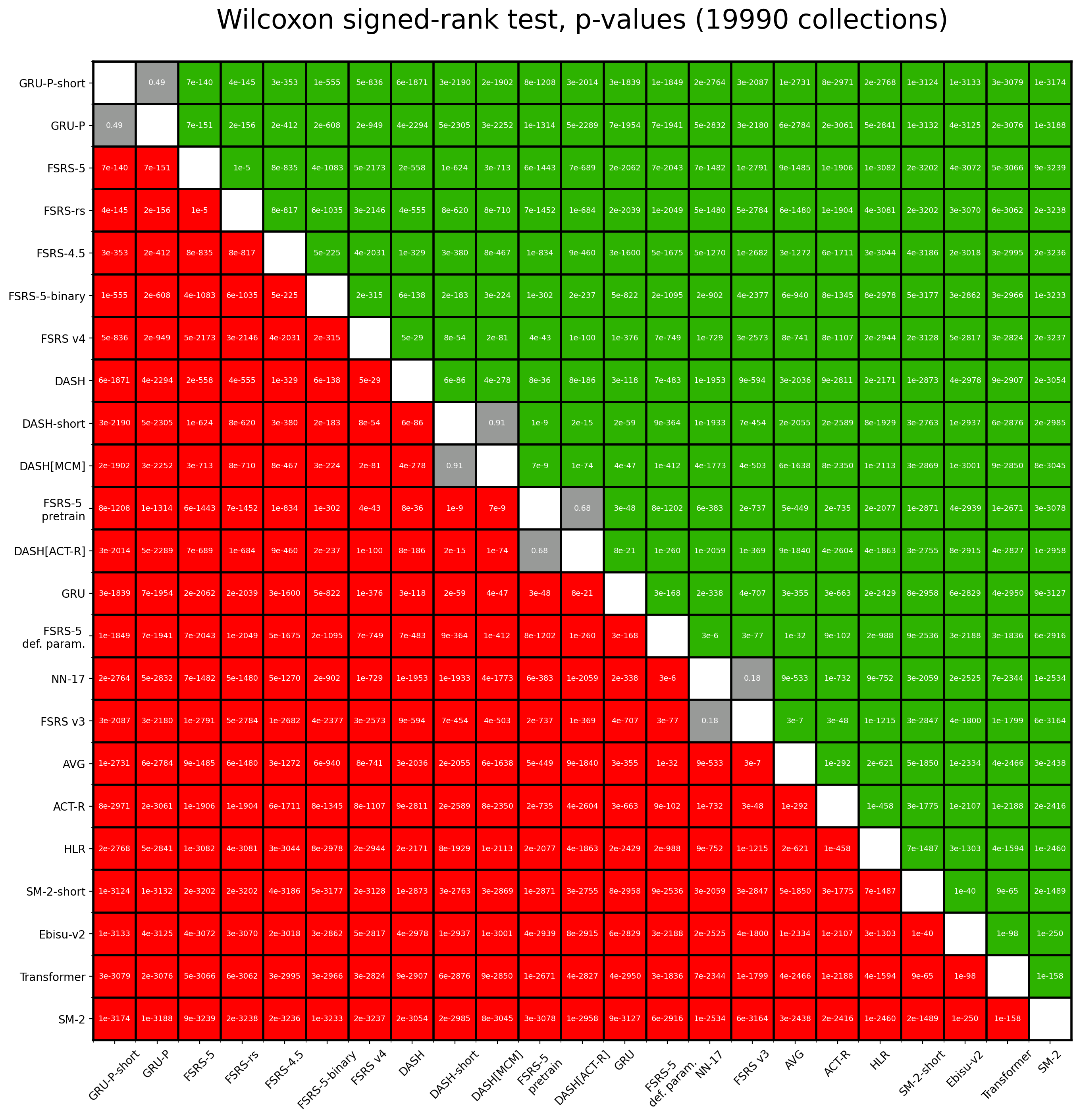
以下の画像は、すべてのアルゴリズムのペアのRMSEに対してWilcoxon符号付き順位検定を実行して得られたp値を示しています。赤は行のアルゴリズムが対応する列のアルゴリズムよりも劣ることを意味し、緑は行のアルゴリズムが対応する列のアルゴリズムよりも優れていることを意味します。灰色はp値が0.01より大きいことを意味し、どちらのアルゴリズムが優れているか結論を出せないことを示します。
ほとんどすべてのp値は非常に小さく、0.01よりも何桁も小さいです。もちろん、これほど低いp値は「これらの値を信頼できるのか?」という疑問を投げかけます。scipy.stats.wilcoxon自体はn>50の場合に近似を使用しており、我々の修正された実装は64ビット浮動小数点数の制限を避けるために、p値自体ではなくp値の小数対数を返す近似を使用しています。したがって、これは近似の近似です。しかし、より重要なのは、このテストが重み付けされていないことであり、RMSEがレビュー数に依存するという事実を考慮していないことです。
全体として、これらのp値は定性的(しかし定量的ではない)レベルで信頼できます。
デフォルトパラメーター
FSRS-5:
0.4197, 1.1869, 3.0412, 15.2441,
7.1434, 0.6477, 1.0007, 0.0674,
1.6597, 0.1712, 1.1178,
2.0225, 0.0904, 0.3025, 2.1214,
0.2498, 2.9466,
0.4891, 0.6468
SuperMemo 15/16/17との比較
以下のリポジトリを参照してください:
ベンチマークの実行方法
必要条件
データセット(小規模版): https://github.com/open-spaced-repetition/fsrs-benchmark/issues/28#issuecomment-1876196288
依存関係:
pip install -r requirements.txt
コマンド
FSRS-4.5:
python script.py
FSRS-4.5 with default parameters:
DRY_RUN=1 python script.py
FSRS-rs:
FSRS_RS=1 FSRS_NO_OUTLIER=1 PYTHONPATH=~/Codes/anki/out/pylib:~/Codes/anki/pylib python script.py
PYTHONPATH変数をAnkiのソースコードのパスに変更してください。
FSRSv4/FSRSv3/HLR/LSTM/SM2:
MODEL=FSRSv4 python other.py
MODEL変数をFSRSv3、HLR、GRU、またはSM2に変更して、対応するモデルを実行してください。
fsrs-optimizerでの開発モデル:
DEV_MODE=1 python script.py
fsrs-optimizerリポジトリをこのリポジトリと同じディレクトリに配置してください。